H2: WP/WG compared to SP/WG (effect of strong pair under the weak group setting)
The second set of hypotheses deals with predictions about the SP/WG setting relative to the WP/WG setting. Under the SP/WG setting, M-subjects can use cheap action and cheap talk to attempt to induce A-subjects to trust him/her. Recall that during the cheap action phase, each player received a flat payment of $0.50 each round independent of the decision he/she made. At the end of the cheap action phase, each A-subject observes his/her M-partner's fraud level for those rounds. Knowing this, M-subjects could attempt to build trust during the cheap talk phase by sending the (cheap talk) message "I will chose 1 this round" and by selecting the cooperate choice, f1. This gives M-subjects the possibility of conditioning the expectations of the A-subjects during the cheap action phase. In addition, each M-subject can further condition his/her partner's expectations during the regular play phase by sending the cheap talk message "I will chose 1 this round".
Previous experimental research has shown that nonbinding communications can enhance mutual cooperation in coordination games where both parties benefit from cooperation (Cooper et al. 1989). In addition, research has shown that certain types of cheap talk can enhance cooperation in a prisoners' dilemma game, where players have symmetric payoffs and both can credibly commit to punish a defector. However, the audit trust game differs from the coordination and prisoners' dilemma games because of asymmetric payoffs and information. Thus, the reliance on cheap talk that existed in coordination and prisoners' dilemma games may not be observed in my setting.19
However, cheap action/talk may be a useful coordination mechanism in my setting if M-subjects are trustworthy. If A-subjects perceive their M-partners to be trustworthy (due to cheap talk/action), the expected damages to the A-subject are perceived to be lower. This in turn should induce the A-subject's to select the trust belief and both players benefit, relative to the Nash combination. The benefits to A-subjects from coordination with M-subjects can be seen by considering the A-subject's objective function (which is reproduced below). The only element in the objective function that cheap talk/action affects is D(f), which is determined by the M-subject. If the A-subject expects low damages because the M-subject cooperates, the A-subject's best response is to trust.
 (1-reproduced)
(1-reproduced)
To test whether cheap action combined with cheap talk creates an environment for self-serving bias to exist, I compare A-subjects' beliefs under the SP/WG settings with those from the WP/WG setting. If A-subjects choose the trust belief more frequently under the SP/WG setting than under the WP/WG setting (and M-subjects do not reciprocate by cooperating), I conclude that self-serving bias is created by the cheap talk/cheap action treatment. Under both settings, economic theory suggests that A-subjects know M-subjects' incentives and anticipate their strategies, and thus cheap action/ talk should not affect the beliefs of A-subjects. The null and the competing hypotheses are stated below:
| H2(Null) | : | There are no differences between A-subjects' beliefs across the WP/WG and SP/WG settings. |
| H2(SSB) | : | A-subjects select the trust belief, f1A, more frequently under the SP/WG setting than under the WP/WG setting. |
The difference between the levels of the trust belief chosen under the SP/WG and the WP/WG settings will serve as a baseline measure of self-serving bias.
H3: WP/WG compared to WP/SG (effect of strong group)
The third set of hypotheses deals with the strong group effect under the WP setting. The strong group manipulation is intended to create cohesion among A-subjects (from having name tags, working together on the quiz, etc.), which in turn increases the social pressure to conform to group goals and raises the psychological cost of liability. Thus, subjects can "save face" by selecting the defensive belief (see Ho 1976 for a discussion of face saving). Kachelmeier and Shehata (1997) find that the observability of actions can influence behavior in some setting.
There are several ways to incorporate this psychological cost into an A-subject's objective function, but a simple approach is to add a cost that is perceived by an individual A-subject i to be a relative comparison of his/her own decisions to other A-subjects decisions, denoted as j (shown as G in the A-subject's modified objective function shown below). Of course there are various ways to model the effect of group membership, but the important element is that the expected cost of liability increases.
 (3)
(3)
Thus, if the procedures used under the SG setting are salient, A-subjects will perceive an additional cost and thus trust M-subjects less under the SG setting than under the WG setting. However, if A-subjects do not attach any psychological cost to identification, the economics should dominate and the SG setting should not differ from the WG setting. The null and competing hypotheses are stated below:
| H3(Null) | : | There are no differences between A-subjects' beliefs across the WP/WG and WP/SG settings. |
| H3(Group effect) | : | A-subjects tend to trust their counterpart less (i.e., increase their selection of the Nash belief, f2A and/or the defensive belief, f3A) under the WP/SG setting than under the WP/WG setting. |
H4: WP/WG compared to SP/SG (effect of strong pair and strong group)
The fourth set of hypothesis compares A-subjects' beliefs across the WP/WG and SP/SG settings. The null hypothesis states that there are no differences between A-subjects' beliefs under WP/WG and SP/SG settings because strong pair effect neutralizes the strong group effect. The alternative makes a nondirectional prediction that the two forces will not completely balance each other out. In the results I investigate various ways the two settings can differ, including the effects on M-subjects' choices. The null and the alternative hypotheses are stated below:
| H4(Null) | : | There are no differences between A-subjects' beliefs across the WP/WG and SP/SG settings. |
| H4(Group effect does not perfectly neutralizes the Pair effect) | : | A-subjects' beliefs under the WP/WG and SP/SG settings are different. |
H5: SP/WG compared to SP/SG (effect of strong group treatment under the strong pair settings)
Under this set of hypotheses I investigate whether the self-serving bias (if it exists) under the SP/WG setting can be reduced by the strong group treatment. Specifically, the alternative predicts that the strong group effect is salient under the strong pair setting, thus neutralizing the self-serving bias. The arguments for the above hypotheses applies, thus making this set of hypotheses a "horse race" between the noneconomic forces. The null and competing hypotheses are stated below:
| H5(Null) | : | There are no differences between A-subjects' beliefs across the SP/WG and SP/SG settings. |
| H5(Group effect) | : | A-subjects under the SP/SG setting are less trusting than A-subjects under the SP/WG setting. |
H6: Comparing A-subjects' beliefs from the resolution rounds to the regular play rounds
A-subjects are informed of his/her M-partner's choices at the end of the regular play phase, but not his/her own actual level of liability. H6 investigates the effect of this information on A-subjects' belief selection. The null hypothesis predicts that there will be no differences between A-subjects' choices during the regular play rounds and those from the resolution rounds. This is consistent with the notion that A-subjects expect M-subjects to be untrustworthy and the information of the fraud level of M-subject does not change A-subjects' beliefs (i.e., A-subject beliefs are in "steady state"). The alternative predicts that A-subjects will change their frequency of choosing the trust belief after learning M-subjects' fraud level. The alternative is based on the fact that A-subjects do not have information about the M-subjects during the regular play rounds, and thus may be overly trusting of M-subjects during the regular play phase.
| H6(Null) | : | A-subjects' frequency of selecting the trust belief, f1A, will be the same across the regular play phase and the resolution phase. |
| H6(Alternative) | : | A-subjects' frequency of selecting the trust belief, f1A, will decrease across the regular play phase and the resolution phase. |
V. Results
Table 4 summarizes both players' choices under the four settings for the regular play and resolution phases. Using the WP/WG setting as an example to interpret the table, Row 1 of Panel A shows that A-subjects choose the trust belief, f1A, 85 times out of 203 opportunities (42%), the Nash belief, f2A, 69 times (34%), and the defensive belief, f3A, 49 times (24%). The fourth column shows that there are 203 decisions20 made by A-subjects during the regular play phase and column 5 shows that the average belief is 1.82 (calculated by setting f1A = 1, f2A = 2, f3A = 3). My primary analysis investigates proportions of aggregate belief/fraud levels for subjects. This data aggregation approach is used to highlight the general tendencies of the data. A second data aggregation method would be to define an observation as the cumulated decisions of a subject. There are eleven subject-pairs in each setting; thus generating a total of 44 individual subject observations. The results using 44 observations produces lower significance levels, but the same qualitative results. In general, statistical tests performed on experimental data are used to supplement results that are recognizable using an "interocular test" which is the intent in this paper. See Davis and Holt (1993) for a discussion of statistical analysis of experimental data.
Row 5 of Panel A of Table 4 shows A-subjects' choices during the resolution phase of WP/WG. The frequencies (percentage) that each belief is chosen are 23 (35%), 17 (26%), and 26 (39%) for trust, Nash, and defensive belief, respectively, with 66 choice opportunities,21 and an average belief of 2.05. Row 1 of Panel B shows that the frequencies of each fraud level selected by M-subjects during the regular play phase of the WP/WG setting are 49 (24%), 61 (30%), and 93 (46%) for the cooperate, Nash, and cheat fraud choices, respectively, and average fraud of 2.22 (calculated by setting f1 = 1, f2 = 2, f3 = 3). M-subjects' choices during the resolution phase are shown in Row 5 of Panel B as 26 (40%), 16 (24%), and 24 (36%) for cooperate, Nash, and cheat, respectively, and with the average fraud of 1.97. Figures 3-6 graphically presents the data from the regular play phase.
|
|
|
|
|
|
|
|
|
|
Table 4. A-subjects' Beliefs and M-subjects' Fraud Levels for the Four Settings subdivided into Regular Play and Resolution Phases
|
|
|
|
|
|
|
|
|
|
|
Panel A: A-subjects' Beliefs
|
|
|
|
|
|
|
Regular Play Phase
|
Trust
f1A
|
Nash
F2A
|
Defensive
f3A
|
Total
|
Average Belief2
|
|
|
|
WP/WG1
|
85 (42%)
|
69 (34%)
|
49 (24%)
|
203
|
1.82
|
|
|
|
SP/WG
|
139 (68%)
|
22 (11%)
|
42 (21%)
|
203
|
1.52
|
|
|
|
WP/SG
|
61 (31%)
|
39 (20%)
|
98 (49%)
|
198
|
2.19
|
|
|
|
SP/SG
|
97 (48%)
|
31 (15%)
|
75 (37%)
|
203
|
1.89
|
|
|
|
|
|
|
|
|
|
|
Resolution Phase
|
|
|
|
|
|
|
|
|
WP/WG
|
23 (35%)
|
17 (26%)
|
26 (39%)
|
66
|
2.05
|
|
|
|
SP/WG
|
31 (47%)
|
10 (15%)
|
25 (38%)
|
66
|
1.91
|
|
|
|
WP/SG
|
18 (28%)
|
10 (16%)
|
36 (56%)
|
64
|
2.28
|
|
|
|
SP/SG
|
19 (29%)
|
14 (21%)
|
33 (50%)
|
66
|
2.21
|
|
|
|
|
|
|
|
|
|
|
|
Panel B: M-subjects' Fraud Level
|
|
|
|
|
|
|
Regular Play Phase
|
Cooperate
f1
|
Nash
f2
|
Cheat
f3
|
Total
|
Average Fraud Level3
|
|
|
|
WP/WG
|
49 (24%)
|
61 (30%)
|
93 (46%)
|
203
|
2.22
|
|
|
|
SP/WG
|
49 (24%)
|
28 (14%)
|
126 (62%)
|
203
|
2.38
|
|
|
|
WP/SG
|
81 (41%)
|
49 (25%)
|
68 (34%)
|
198
|
1.93
|
|
|
|
SP/SG
|
51 (25%)
|
48 (24%)
|
104 (51%)
|
203
|
2.26
|
|
|
|
|
|
|
|
|
|
|
Resolution Phase
|
|
|
|
|
|
|
|
|
WP/WG
|
26 (40%)
|
16 (24%)
|
24 (36%)
|
66
|
1.97
|
|
|
|
SP/WG
|
31 (47%)
|
22 (33%)
|
13 (20%)
|
66
|
1.73
|
|
|
|
WP/SG
|
16 (25%)
|
16 (25%)
|
32 (50%)
|
64
|
2.25
|
|
|
|
SP/SG
|
22 (33%)
|
26 (40%)
|
18 (27%)
|
66
|
1.94
|
|
|
|
|
|
|
|
|
|
|
1 WP/WG = Weak Pair Weak Group setting
SP/WG = Strong Pair Weak Group setting
WP/SG = Weak Pair Strong Group setting
SP/SG = Strong Pair Strong Group setting
2 Average beliefs are calculated by setting f1A = 1, f2A = 2, f3A = 3.
3 Average fraud levels are calculated by setting f1 = 1, f2 = 2, f3 = 3.




Results for H1: Hypotheses for the WP/WG setting (establishing a baseline setting for A-subjects' beliefs)
This hypothesis investigates A-subjects' beliefs under the WP/WG setting. The analysis is summarized in Table 5. Panel A addresses H1(null), which predicts that A-subjects' beliefs are uniformly distributed across the three belief options. There are 203 A-subject observations under this regime and thus the predicted frequency for each belief choice is 67.67, if uniformly distributed. As shown in Panel A, the actual frequencies (percentages) for the regular play phase are 85 (42%), 69 (34%), and 49 (24%) for the trust, Nash, and defensive belief, respectively. The hypothesis that these choices are uniformly distributed is rejected (p<0.01) using a chi-square test. This finding motives an investigation of the patterns chosen by A-subjects.22
Panel B of Table 5 investigates the two competing hypotheses. The Nash alternative hypothesis predicts that A-subjects will select f2A more than 33% of the time. I use 33% as a benchmark for both the Nash alternative and the Trust alternative to standardize the comparisons between the two competing hypotheses. As shown in Panel B of Table 5, the Nash belief is chosen 34% of the time. Using a one-tailed test of proportions, A-subjects' choices of the Nash belief is not significantly different from 33%, indicating that A-subjects do not choose the Nash option more frequently. Panel B also shows the results of a one-tailed test of proportions for H1(Trust), which predicts that f1A will be chosen more than 33% of the time. I find support for this hypothesis (p<0.008), indicating that the trust belief is chosen more frequently under the WP/WG setting. I will discuss mean beliefs and fraud levels later in this section.
Panel C of Table 5 investigates the extent to which the beliefs of A-subjects correspond to M-subjects' fraud levels. Recall that the payoffs for the A-subjects are designed such that A-subjects maximize profits by selecting a belief that corresponds his/her M-partner's chosen fraud level (i.e., f*A = f. For the WP/WG setting, I first determine whether A-subjects' beliefs differ from M-subjects' fraud levels by comparing the frequency of each belief chosen by A-subjects (denoted as #(fiA)) to the frequency of each fraud level chosen by M-subjects (denoted as #(fj)). I find the frequency of A-subjects' beliefs do not equal the proportion of M-subjects' fraud levels, using a chi-square test (p<0.00). I next apply a one-tailed test of proportions to examine how the two sets of proportions differ. As shown in Panel C of Table 5, I find that A-subjects select a higher proportion of the trust belief than M-subjects select the cooperate choice (p<0.00) and M-subjects select a higher proportion of the cheat choice than A-subjects select the defensive belief (p<0.00). There is no significant difference between the proportion of Nash choices for the two players.
Figure 3 graphically displays the data under the WP/WG setting. The figure reinforces the results from Table 5 that A-subjects select the trust belief most frequently and M-subjects select the cheat choice most frequently. The results indicate a mismatch that is detrimental to the A-subjects. The fact that A-subjects trusts M-subjects (and M-subjects do not deserve the trust) could be interpreted as a type of self-serving bias. However, as discussed below, I define self-serving bias as the increase in the trust belief by A-subject under a setting, relative to the WP/WG setting.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 5: Examination of H1(Null), H1(Nash), and H1(Trust)- Establishing a Benchmark for the Weak Pair/ Weak Group Setting (Regular Play Phase)
|
|
|
|
Panel A
|
Examination of H1(Null)
|
|
|
|
|
H1(Null):
|
Are A-subjects' beliefs random under the WP/WG setting?
|
|
|
|
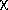 2 - test 2 - test
|
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
Total
|
Average
beliefs
|
|
|
|
Actual frequency
|
85 (42%)
|
69 (34%)
|
49 (24%)
|
203
|
1.82
|
|
|
|
Expected frequency
|
67.67
|
67.67
|
67.67
|
203
|
|
|
|
|
|
|
Pr(X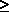 2 )= 2 )=
|
0.008
|
Conclude: beliefs are not random
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel B
|
Examination of H1(Nash) and H1(Trust)
|
|
|
|
|
H1(Nash):
|
Do A-subjects select f2A more than a third of the time?
|
|
|
|
H1(Trust):
|
Do A-subjects select f1A more than a third of the time?
|
|
|
|
One-tailed test of proportions
|
Trust
f1A
|
Nash
f2A
|
|
|
|
|
Proportion
|
0.42
|
0.34
|
|
|
|
|
Expected
|
0.33
|
0.33
|
|
|
|
|
Z-score
|
2.39
|
0.12
|
|
|
|
|
Pr(Z Zc)
|
0.008
|
0.451
|
|
|
|
|
Conclude
|
Trust beliefs are selected more than 1/3 of the time
|
Nash beliefs are not selected more than 1/3 of the time
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel C
|
Do A-subjects' beliefs differ from M-subjects' fraud levels under the WP/WG setting?
|
|
|
|
|
|
|
|
|
2 - test
|
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
|
WP/WG
|
|
(85, 49)
|
(69, 61)
|
(49, 93)
|
|
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
Conclude: choices differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
One-tailed test of proportions
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
|
Proportion
|
(0.42, 0.24)
|
(0.34, 0.30)
|
(0.24, 0.46)
|
|
|
|
|
|
Difference
|
0.17
|
0.03
|
-0.21
|
|
|
|
|
|
Z-score
|
3.69
|
0.74
|
4.47
|
|
|
|
|
|
Pr(Z Zc)
|
0.000
|
0.228
|
0.000
|
|
|
|
|
|
Conclude
|
Proportions differ
|
Proportions do not differ
|
Proportions differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Results for H2: Hypotheses comparing the WP/WG setting to the SP/WG setting (what is the effect on A-subjects' beliefs of the strong pair treatment under the weak group setting?)
Table 6 provides a summary of the test results for H2. Panel A shows that during the regular play phase of the SP/WG setting, the frequencies (percentages) of trust, Nash, and defensive beliefs chosen by A-subjects are 139 (68%), 22 (11%), and 42 (21%) respectively. Panel A also shows a chi-square test comparing A-subjects' choices under the SP/WG and WP/WG settings. The null hypothesis of no differences is rejected (p<0.00), indicating that A-subjects' beliefs differ across the two settings. Before I discuss how A-subjects' choices differ across the two settings, I first compare A-subjects' beliefs with M-subjects' fraud levels under the SP/WG setting.
Panel B of Table 6 presents this comparison and shows that A-subjects' beliefs differ significantly from M-subjects' fraud levels (p<0.00). A one-tailed test of proportions reported in Panel B shows that the proportion of A-subjects' trust beliefs differ significantly from the proportion of M-subjects' cooperate choices and also the defensive beliefs and cheat choices (p<0.00). However, the proportion of A- and M-subjects' Nash choices do not differ significantly. That is, A-subjects trust M-subjects more frequently, while M-subjects cheat more frequently. Figures 3 and 4 are graphical representations of A-subjects' beliefs for the two setting for the regular play phase. Note the visible spike at the trust-cheat combination under the SP/WG setting relative to the WP/WG setting.
Panel C of Table 6 builds on panel A by investigating A-subjects' choice differences under the SP/WG and WP/WG settings. Using a one-tailed test of proportions, I find the trust and Nash beliefs differ (p<0.00) across the two settings, but not the defensive belief (p<0.238). Specifically, results from the one-tailed test show that A-subjects choose the trust belief more frequently under the SP/WG setting but the Nash belief more frequently under the WP/WG setting, indicating that A-subjects under the SP/WG setting have a significantly higher level of self-serving bias. This finding is consistent with the findings of Bazerman et al. (1997) that decision-makers can be induced to reveal a self-serving bias. In this case, cheap action and cheap talk on the part of M-subjects increase the level of trust by A-subjects under the SP/WG setting over that of the WP/WG, even though trust increases A-subjects' potential risk of liability.
Panel D shows the frequencies and percentages of M-subjects' fraud levels under the SP/WG and WP/WG settings. A chi-square test shows that M-subjects' choices differ significantly across the two settings (p<0.00). Panel E of Table 6 shows M-subjects do not differ in their proportion of cooperate choices, but do for the Nash and cheat choices (p<0.00). M-subjects under the SP/WG setting select the cheat choice 62% of the time (126 times out of 203 opportunities), versus 46% (93 times out of 203 opportunities) under the WP/WG setting. This 16% difference can be interpreted the additional fraud generated due to A-subjects' trust of M-subjects.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 6: Examination of H2 - Comparing the Strong Pair/Weak Group Setting
to the Weak Pair/Weak Group Setting (Regular Play Phase)
|
|
|
|
|
Panel A
|
|
|
|
|
|
|
|
|
|
H2(Null):
|
Do A-subjects' beliefs differ across the WP/WG and SP/WG settings?
|
|
|
2 - test
|
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
Total
|
Average
Beliefs
|
|
|
|
WP/WG
|
|
85 (42%)
|
69 (34%)
|
49 (24%)
|
203
|
1.82
|
|
|
|
SP/WG
|
|
139 (68%)
|
22 (11%)
|
42 (21%)
|
203
|
1.52
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
Conclude: beliefs differ
|
|
|
Panel B
|
|
|
|
|
|
|
|
|
Do A-subjects' beliefs correspond to M-subjects' fraud levels under SP/WG setting?
|
|
|
|
2 - test
|
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
SP/WG
|
|
(139, 49)
|
(22, 28)
|
(42, 126)
|
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
Conclude: choices do not correspond
|
|
|
One-tailed test of proportions
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
Proportion
|
(0.68, 0.24)
|
(0.11, 0.14)
|
(0.21, 0.62)
|
|
|
|
|
Difference
|
0.44
|
-0.02
|
-0.41
|
|
|
|
|
Z-score
|
8.86
|
0.76
|
8.36
|
|
|
|
|
Pr(Z _Zc)
|
0.000
|
0.225
|
0.000
|
|
|
|
|
Conclude:
|
Choices differ
|
Choices not differ
|
Choices differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel C
|
|
|
|
|
|
|
|
|
|
H2(SSB):
|
Do A-subjects trust M-subjects more under the SP/WG setting than under the WP/WG setting?
|
|
|
|
One-tailed test of proportions
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
|
|
|
|
|
WP/WG
|
85/203 = 0.42
|
69/203 = 0.34
|
49/203 = 0.24
|
|
|
|
|
|
SP/WG
|
139/203 = 0.68
|
22/203 = 0.11
|
42/203 = 0.21
|
|
|
|
|
|
Z-score
|
5.29
|
5.47
|
0.71
|
|
|
|
|
|
Pr(Z Zc)
|
0.000
|
0.000
|
0.238
|
|
|
|
|
|
|
Conclude: different levels of trust
|
|
|
|
Panel D
|
|
|
|
|
|
|
|
|
|
Do M-subjects' fraud levels differ across the WP/WG and SP/WG settings?
|
|
|
2 - test
|
|
Cooperate
f1
|
Nash
f2
|
Cheat
f3
|
Total
|
Average fraud
|
|
|
|
WP/WG
|
|
49 (24%)
|
61 (30%)
|
93 (46%)
|
203
|
2.22
|
|
|
|
SP/WG
|
|
49 (24%)
|
28 (14%)
|
126 (62%)
|
203
|
2.38
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
Conclude: choices differ
|
|
|
|
|
Panel E
|
|
|
|
|
|
|
|
|
|
How do M-subjects' fraud levels differ across the SP/WG and WP/WG settings?
|
|
|
|
One-tailed test of proportions
|
Cooperate
f1
|
Nash
f2
|
Cheat
f3
|
|
|
|
|
|
WP/WG
|
49/203 = 0.24
|
61/203 = 0.30
|
93/203 = 0.46
|
|
|
|
|
|
SP/WG
|
49/203 = 0.24
|
28/203 = 0.14
|
126/203 = 0.62
|
|
|
|
|
|
Z-score
|
-0.12
|
3.84
|
3.19
|
|
|
|
|
|
Pr(Z Zc)
|
0.546
|
0.000
|
0.001
|
|
|
|
|
Conclude: increase in the frequency of the cheat choice under SP/WG
|
|
|
|
|
|
Results for H3: Hypotheses comparing the WP/WG setting to the WP/SG setting (what is the effect on A-subjects' beliefs of the strong group treatment under the weak pair setting?)
Table 7 provides a summary of the test results for H3. Panel A shows that during the regular play phase of the WP/SG setting, the frequencies (percentages) of trust, Nash, and defensive beliefs selected by A-subjects are 61 (31%), 39 (20%), and 98 (49%) respectively. For the same setting, the frequencies (percentages) of cooperate, Nash, and cheat choices selected by M-subjects are 81 (41%), 49 (25%) and 68 (34%) respectively (shown in Table 4). Figure 5 shows the combination of A-subjects' and M-subjects' choices under the WP/SG setting.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 7: Examination of H3 - Comparing the Weak Pair/Strong Group Setting
to the Weak Pair/Weak Group Setting (Regular Play Phase)
|
|
|
|
Panel A
|
|
|
|
|
|
|
|
|
|
H3(Null):
|
Are there differences between A-subjects' beliefs in the WP/WG and WP/SG settings?
|
|
|
2 - test
|
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
Total
|
Average beliefs
|
|
|
|
WP/WG
|
|
85 (42%)
|
69 (34%)
|
49 (24%)
|
203
|
1.82
|
|
|
|
WP/SG
|
|
61 (31%)
|
39 (20%)
|
98 (49%)
|
198
|
2.19
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
Conclude: beliefs differ
|
|
|
|
|
Panel B
|
|
|
|
|
|
|
|
|
|
Do A-subjects' beliefs correspond to M-subjects' fraud levels under the WP/SG setting?
|
|
|
|
|
2 - test
|
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
|
WP/SG
|
|
(61, 81)
|
(39, 49)
|
(98, 68)
|
|
|
|
|
|
|
|
Pr(X>2) =
|
0.009
|
Conclude: choices do not correspond
|
|
|
|
One-tailed test of proportions
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
|
Proportion
|
(0.31, 0.41)
|
(0.20, 0.25)
|
(0.49, 0.34)
|
|
|
|
|
|
Difference
|
-0.10
|
-0.05
|
0.15
|
|
|
|
|
|
Z-score
|
1.99
|
1.09
|
2.95
|
|
|
|
|
|
Pr(Z Zc)
|
0.023
|
0.138
|
0.002
|
|
|
|
|
|
Conclude:
|
Choice differs
|
Choice do not differ
|
Choice differs
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel C
|
|
|
|
|
|
|
|
|
|
Are A-subjects' are more distrusting under the WP/SG setting?
|
|
|
|
One-tailed test of proportions
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
|
|
|
|
|
WP/WG
|
85/203 = 0.42
|
69/203 = 0.34
|
49/203 = 0.24
|
|
|
|
|
|
WP/SG
|
61/198 = 0.31
|
39/198 = 0.20
|
98/198 = 0.49
|
|
|
|
|
|
Z-score
|
2.20
|
3.11
|
5.16
|
|
|
|
|
|
Pr(Z Zc)
|
0.014
|
0.001
|
0.000
|
|
|
|
|
|
|
Conclude: less trust under WP/SG
|
|
|
|
|
Panel D
|
|
|
|
|
|
|
|
|
|
|
Are there differences between M-subjects' fraud levels under the WP/WG and WP/SG settings?
|
|
|
2 - test
|
|
Cooperate
f1
|
Nash
f2
|
Cheat
f3
|
Total
|
Average fraud
|
|
|
|
WP/WG
|
|
49 (24%)
|
61 (30%)
|
93 (46%)
|
203
|
2.22
|
|
|
|
WP/SG
|
|
81 (41%)
|
49 (25%)
|
68 (34%)
|
198
|
1.93
|
|
|
|
|
|
Pr(X2 )=
|
0.001
|
Conclude: choices differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel E
|
|
|
|
|
|
|
|
|
|
|
Do M-subjects committed less fraud under WP/SG than under the WP/WG setting?
|
|
|
|
One-tailed test of proportions
|
Cooperate
f1
|
Nash
f2
|
Cheat
f3
|
|
|
|
|
|
WP/WG
|
49/203 = 0.24
|
61/203 = 0.30
|
93/203 = 0.46
|
|
|
|
|
|
WP/SG
|
81/198 = 0.41
|
49/198 = 0.25
|
68/198 = 0.34
|
|
|
|
|
|
Z-score
|
3.30
|
1.23
|
2.43
|
|
|
|
|
|
Pr(Z Zc)
|
0.000
|
0.110
|
0.007
|
|
|
|
|
Conclude: most cooperate choices and less cheat choices under WP/SG
|
|
Panel A in Table 7 shows that the null hypothesis of no differences in A-subjects' beliefs across the two settings is rejected (p<0.00) using a chi-square test. In Panel B, the results from a chi-square test shows that A- subjects' beliefs differ from M-subjects' fraud levels under the SG/WP setting ((p<0.009). A one-tail test of proportions show that there are significant differences in the frequency of matched choices between the trust belief and cooperate choice and between the defensive belief and the cheat choice, but not for the Nash choices. Specifically, the proportion of M-subjects' cooperate choices is significantly higher than the proportion of A-subjects' trust beliefs and the reverse is true of the cheat choice and defensive belief. That is, A-subjects do not trust M-subjects even though the M-subjects are more trustworthy under this setting.
Panel C of Table 7 builds on panel A by investigating A-subjects' beliefs under the WP/WG and WP/SG settings. Using a one-tailed test of proportions, I find the proportion of each belief differs across the two settings (p<0.014). Specifically, results from the one-tailed test show A-subjects choose the trust and Nash beliefs more frequently and the defensive belief less frequently under the WP/WG setting. This indicates that A-subjects under the WP/SG setting have a significantly lower level of self-serving bias than A-subjects under the SP/WG setting. This finding suggests that the group manipulation is salient.
Panel D shows the frequencies and percentages of M-subjects' fraud levels under the WP/WG and WP/SG settings. A chi-square test shows M-subjects' choices differ significantly across the two settings (p<0.001). Panel E of Table 6 shows M-subjects choices under the two settings differ in their proportions of cooperate and cheat choices (p<0.007), but not in the proportion of Nash choices. M-subjects under the WP/WG setting select the cheat choice 46% of the time (93 times out of 203 opportunities) versus 34% (68 times out of 203 opportunities) under the WP/SG setting. That is, the group treatment decreases the trust of A-subjects, which in turn lowers the level of fraud committed by M-subjects. In this case, the 12% difference represents the decrease in fraud caused by the group treatment on A-subjects. Figure 5 shows that under the WP/SG setting, there is a perceptible increase in the defensive-cooperate combination over that of the WP/WG setting shown in Figure 3.
Results for H4: Hypotheses comparing the WP/WG setting to the SP/SG setting (what is the effect of the strong group treatment on A-subjects' beliefs under the strong pair setting?)
Table 8 summaries the results for H4. Panel A shows that during the regular play phase of the SP/SG setting, the frequencies (percentages) of trust, Nash, and defensive beliefs selected by A-subjects are 97 (48%), 31 (15%), and 75 (37%) respectively. Under the same setting, the frequencies (percentages) of cooperate, Nash, and cheat choices selected by M-subjects are 51 (25%), 48 (24%), and 104 (51%) respectively (see Table 4). Figure 6 shows the A-subjects' and M-subjects' choice combinations under the SP/SG setting.
Panel A in Table 8 reports the results of the chi-square test showing a significant difference between A-subjects' beliefs across the WP/WG and SP/SG settings (p<0.00). This finding indicates that the group effect may either be weaker or stronger than the pair effect. Panel C shows the results of the one-tailed test of proportions comparing each belief. This pair-wise comparison shows significant differences for A-subjects' Nash and defensive beliefs across the two settings (p<0.00). Specifically, A-subjects under the WP/WG setting select the Nash belief more frequently and the defensive belief less frequently than A-subjects under the SP/SG setting. This implies that A-subjects are less trusting of M-subjects under the SP/SG setting. However, the proportions of the trust belief selected by A-subjects are not significantly different under the two settings (p<0.14). This is noteworthy because it indicates that the strong group manipulation neutralizes the self-serving bias created by the strong pair manipulation. In addition, the results show that although there is not a difference in the proportion of trust, A-subjects are more defensive under the SP/SG setting.
In Panel B of Table 8, a chi-square test shows that A- and M-subject choices differ under the SG/SP setting (p<0.000) and a one-tail test of proportions show that there is a significant difference in each of A-subjects' beliefs and corresponding M-subjects' fraud levels (p<0.022). Panel D shows the frequencies and percentages of M-subjects' fraud levels under the WP/WG and SP/SG settings. A chi-square test shows M-subjects' choices do not differ significantly across the two settings. Thus, under the SP/SG setting, A-subjects select a similar proportion of trust beliefs (but different proportions of Nash and defensive beliefs) than under the WP/WG setting and this induces M-subjects do have similar fraud levels across the two regimes.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 8: Examination of H4 - Comparing the Strong Pair/Strong Group Setting
to the Weak Pair/Weak Group Setting (Regular Play Phase)
|
|
|
|
Panel A
|
|
|
|
|
|
|
|
|
|
H4(Null-A):
|
Are there differences between A-subjects' beliefs across the WP/WG and SP/SG settings?
|
|
|
2 - test
|
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
Total
|
Average beliefs
|
|
|
|
WP/WG
|
|
85 (42%)
|
69 (34%)
|
49 (24%)
|
203
|
1.82
|
|
|
|
SP/SG
|
|
97 (48%)
|
31 (15%)
|
75 (37%)
|
203
|
1.89
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
(Reject H4(Null))
|
|
|
|
|
Panel B
|
|
|
|
|
|
|
|
|
|
|
Do A-subjects' beliefs correspond to M-subjects' fraud levels under the SP/SG setting?
|
|
|
|
|
2 - test
|
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
|
SP/SG
|
|
(97, 51)
|
(31, 48)
|
(75, 104)
|
|
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
Conclude: choices do not correspond
|
|
|
|
One-tailed test of proportions
|
(#(f1A), #( f1))
|
(#(f2A), #( f2))
|
(#(f3A), #( f3))
|
|
|
|
|
|
Proportion
|
(0.48, 0.25)
|
(0.15, 0.24)
|
(0.37, 0.51)
|
|
|
|
|
|
Difference
|
0.22
|
-0.08
|
-0.14
|
|
|
|
|
|
Z-score
|
4.64
|
2.01
|
2.80
|
|
|
|
|
|
Pr(Z Zc)
|
0.000
|
0.022
|
0.003
|
|
|
|
|
|
Conclude
|
Choices differ
|
Choices differ
|
Choices differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel C
|
|
|
|
|
|
|
|
|
|
H4(Trust):
|
Are A-subjects' less trusting under the SP/SG setting?
|
|
|
|
One-tailed test of proportions
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
|
|
|
|
|
WP/WG
|
85/203 = 0.42
|
69/203 = 0.34
|
49/203 = 0.24
|
|
|
|
|
|
SP/SG
|
97/203 = 0.48
|
31/203 = 0.15
|
75/203 = 0.37
|
|
|
|
|
|
Z-score
|
1.10
|
4.26
|
2.69
|
|
|
|
|
|
Pr(Z Zc)
|
0.136
|
0.000
|
0.004
|
|
|
|
|
|
|
Conclude: no difference in trust choice
|
|
|
|
|
Panel D
|
|
|
|
|
|
|
|
|
|
|
Are there differences between M-subjects' fraud levels under the WP/WG and SP/SG settings?
|
|
|
2 - test
|
|
Cooperate
f1
|
Nash
f2
|
Cheat
f3
|
Total
|
Average
Fraud
|
|
|
|
WP/WG
|
|
49 (24%)
|
61 (30%)
|
93 (46%)
|
203
|
2.22
|
|
|
|
SP/SG
|
|
51 (25%)
|
48 (24%)
|
104 (51%)
|
203
|
2.26
|
|
|
|
|
|
Pr(X2 )=
|
0.332
|
Conclude: choices do not differ
|
|
|
|
|
|
|
|
|
|
|
|
|
Results for H5: Hypotheses comparing A-subjects' beliefs under the SP/WG and SP/SG settings (does self-serving bias that arises under the SP/WG setting decrease due to the strong group treatment?)
Table 9 summaries the results for H5 with Panel A showing a chi-square test comparing A-subjects' beliefs under the two settings. The null of no differences between A-subjects' beliefs under the SP/WG and SP/SG settings is rejected (p<0.00). Also shown in the bottom part of Panel A is a comparison of A-subjects' responses to their M-partners' cheap talk proposals under the two settings. M-subjects sent 192 and 170 messages to signal cooperation during the regular play phase under the SP/WG and SP/SG settings, respectively. As shown in the table, A-subjects under the SP/WG setting respond to the cheap talk proposals by selecting the trust belief 138 times out of the 192 opportunities (72%) and A-subjects under the SP/SG setting respond to the cheap talk proposal by selecting the trust belief 86 times out of the 170 opportunities (51%). A test of proportions on A-subjects' responses to their M-partners' cheap talk proposals rejects (p<0.00) the null of no differences in A-subjects' behavior across the two settings.
Panel B of Table 9 shows the one-tailed test of proportions on A-subjects' beliefs under the two settings. The pair-wise comparison shows that there are significant differences for the trust and defensive beliefs (p<0.00) but not for the Nash belief (p<0.119). A-subjects under the SP/WG setting select the trust belief more frequently and A-subjects under the SP/SG setting select the defensive belief more frequently.
Panel C shows the frequencies and percentages of the fraud levels of M-subjects under the WS/WG and SP/SG settings. A chi-square test shows that M-subjects' choices differ significantly across the two settings (p<0.025). Panel D of Table 9 shows M-subjects do differ in their proportion of choices for the Nash and cheat choices (p<0.018), but not for the cooperate choices. M-subjects under the SP/WG setting select the cheat choice 62% of the time (126 times out of 203 opportunities) versus 51% (104 times out of 203 opportunities) under the WP/SG setting. The 11% difference represents the change in M-subjects' fraud level caused by the group pressure on A-subjects. Thus, under the SP/SG setting, A-subjects are less trusting of their M-partners than under the SP/WG setting and this induces M-subjects to cheat less. This can also be seen by comparing Figures 4 and 6.
|
|
|
|
|
|
|
|
|
|
|
|
Table 9: Examination of H5 - Comparing the Strong Pair/Weak Group Setting
to the Strong Pair/Strong Group Setting (Regular Play Phase)
|
|
|
Panel A
|
|
|
|
|
|
|
|
|
|
H5(Null):
|
Are there differences between A-subjects' beliefs across the SP/WG and SP/SG settings?
|
|
|
A-subjects' beliefs
|
|
|
|
|
|
|
|
|
2 - test
|
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
Total
|
Average beliefs
|
|
|
|
SP/WG
|
|
139 (68%)
|
22 (11%)
|
42 (21%)
|
203
|
1.52
|
|
|
|
SP/SG
|
|
97 (48%)
|
31 (15%)
|
75 (37%)
|
203
|
1.89
|
|
|
|
|
|
Pr(X2 )=
|
0.000
|
Conclude: Choices differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
How do A-subjects' respond to M-subjects' proposal?
|
|
|
|
|
|
|
One-tailed test of proportions
|
f1A | M sent a Proposal
|
|
|
|
|
|
|
SP/WG
|
138/192 = 0.72
|
|
|
|
|
|
|
SP/SG
|
86/170 = 0.51
|
|
|
|
|
|
|
Z-score
|
4.16
|
|
|
|
|
|
|
Pr(Z Zc)
|
0.000
|
|
|
|
|
|
|
Conclude
|
Responses differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel B
|
|
|
|
|
|
|
|
|
|
H5(Group):
|
Are A-subjects less trusting under the SP/SG than under the SP/WG setting?
|
|
|
|
One-tailed test of proportions
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
|
|
|
|
|
SP/WG
|
139/203 = 0.68
|
22/203 = 0.11
|
42/203 = 0.21
|
|
|
|
|
|
SP/SG
|
97/203 = 0.48
|
31/203 = 0.15
|
75/203 = 0.37
|
|
|
|
|
|
Z-score
|
4.12
|
1.18
|
3.51
|
|
|
|
|
|
Pr(Z Zc)
|
0.000
|
0.119
|
0.000
|
|
|
|
|
|
|
Conclude: Lower frequencies of trust choice
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel C
|
|
|
|
|
|
|
|
|
|
|
Are there differences between M-subjects' fraud levels under the SP/WG and SP/SG settings?
|
|
|
2 - test
|
|
Trust
f1A
|
Nash
f2A
|
Defensive
f3A
|
Total
|
Average fraud
|
|
|
|
SP/WG
|
|
49 (24%)
|
28 (14%)
|
126 (62%)
|
203
|
2.38
|
|
|
|
SP/SG
|
|
51 (25%)
|
48 (24%)
|
104 (51%)
|
203
|
2.26
|
|
|
|
|
|
Pr(X2 )=
|
0.025
|
Conclude: choices differ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Panel D
|
|
|
|
|
|
|
|
|
|
|
Do M-subjects committed less fraud under SP/SG than under SP/WG?
|
|
|
|
One-tailed test of proportions
|
Cooperate
f1
|
Nash
f2
|
Cheat
f3
|
|
|
|
|
|
SP/WG
|
49/203 = 0.24
|
28/203 = 0.14
|
126/203 = 0.62
|
|
|
|
|
|
SP/SG
|
51/203 = 0.25
|
48/203 = 0.24
|
104/203 = 0.51
|
|
|
|
|
|
Z-score
|
0.12
|
2.42
|
2.10
|
|
|
|
|
|
Pr(Z Zc)
|
0.454
|
0.008
|
0.018
|
|
|
|
|
|
|
Conclude: higher frequency of cheat choices
|
|
|
Results for H6: Hypothesis comparing A-subjects' beliefs across the resolution and regular play phases
H6(null) predicts that A-subjects will not change their frequency of selecting the trust belief after observing M-subjects' choices. That is, the frequency of trust choices will be the same during the resolution phase as during the regular play phase. Table 4 summarizes the relevant data. During the resolution phase of WP/WG, A-subjects choose the trust belief 35% of the time (23 times out of 66 opportunities) versus 42% of the time (85 times out of 203 opportunities) for the regular play phase. This difference is significant using a one tail test of proportion (p<0.02). The differences across the resolution and regular play phases are also significant for SP/WG and SP/WG, (p<0.02) but not for the WP/SG setting. Thus, when A-subjects are under the strong group setting and M-subjects cannot engage in cheap action/talk, the information about the M-subjects' fraud choices does not change A-subjects' propensity to trust their M-partner. This suggests that A-subjects' strategies are relatively stable under this regime and that the information about M-subject choices does not materially change the strategies of A-subjects.
Summary of the results using subjects' average choices
The right-hand column of Table 4 shows the average beliefs of A-subjects and average fraud levels of M-subjects. The pair combinations of average beliefs and average fraud levels under the WP/WG, SP/WG, WP/SG, SP/SG settings are (1.82, 2.22), (1.52, 2.38), (2.19, 1.93), and (1.89, 2.26) respectively. These data are shown graphically in Figure 7 and confirm the findings discussed above. More importantly, M-subjects' fraud levels are always higher than A-subjects' beliefs, except under the WP/SG setting. Figure 8 plots the average pair combinations as ordered pairs. Average A- subjects' beliefs are plotted on the horizontal axis and average M-subjects' fraud levels are plotted on the vertical axis for the four settings. Note that under the SP/WG, WP/WG, and SP/SG settings M-subjects have higher average fraud levels than their A-partners' average beliefs (above the 45 degree line) indicating that A-subjects are overly trusting of their M-partners. However, under the WP/SG setting, the average level of M-subjects' fraud is below A-subjects' average belief (below the 45-degree line) indicating relative distrust by the A-subjects. Figure 8 shows that under the SP/WG setting, M-subjects have the highest average fraud level and A-subjects' have the lowest average belief of fraud (i.e., A-subjects are most trusting) compared to the other three setting. On the opposite extreme, under the WP/SG setting M-subjects have the lowest average fraud level and A-subjects' have the highest average belief of fraud (i.e., A-subjects are least trusting). In the middle are the WP/WG and SP/SG settings, where M-subjects have roughly the same level of average fraud and A-subjects have roughly the same level of average beliefs.
Figure 9 duplicates the data from Figure 8 for the regular play phase, but also include the data from the resolution phase. The data are ordered pairs of average subject choices, with lines beginning at average choice values for the regular play phase and ending at average choice values for the resolution phase. For example, the line for the SP/WG setting begins at the point comprised of the average belief of 1.52 and the average fraud of 2.38 for this setting. The line and arrow pointing down and to the right (stopping at 1.91, 1.73) represent the average choice pair for the resolution phase. Note that under the SP/WG, WP/WG, and SP/SG settings, the average beliefs increased, and average fraud levels decreased in the resolution phase. That is, after A-subjects observed M-subjects fraud levels for the regular play phase rounds, A-subjects became less trusting and M-subjects committed less fraud. However, under the WP/SG setting, the average belief increases slightly and the fraud increases considerably in the resolution phase.



VI. Conclusions
A primary role of independent auditing is to enhance the credibility of financial statements. In order for audits to generate credibility, auditors must represent the interests of external parties, not those of management. For the past 30 years policy makers have debated the extent to which auditors can provide high quality audits (Pitt and Birenbaum 1997; MacDonald 1999; United States Senate 1977). Some conditions identified as having the potential to reduce audit quality include (1) lowballing, which involves setting audit fees in early periods below the cost of the audit (Craswell and Francis 1999; DeAngelo 1981; Dye 1991), (2) the provision of management advisory services (Antle et al. 1997; Dopuch and King 1991), and (3) direct and indirect financial and family ties (Fardella et al. 2000; Wallman 1996). These conditions are argued to lower audit quality because they increase managers' leverage over auditors. However, there are counterbalancing forces that reduce auditors' incentives to misreport, such legal sanctions imposed by courts/regulators and market penalties associated with the loss of reputational capital. Thus, auditors face tradeoffs between economic rents from misreporting and the potential imposition of economic penalties for misreporting. The debate in the policy arena is typically over the strength of each of these forces (General Accounting Office 1996; Public Oversight Board Advisory Panel On Auditor Independence 1994).
As an alternative to economic analysis, some researchers believe that audit quality may be reduced due to psychological reasons. For example, Bazerman et al. (1997) argue that even honest auditors cannot conduct impartial audits under existing conditions due to self-serving biases. The purpose of my research is to investigate self-serving bias in an experimental environment that incorporates both economic and psychological issues. The approach of combining both psychological and economic factors has been suggested by a variety of authors, including Kachelmeier (1996a) and King (1991).
The experimental results show that a self-serving bias does arise under my setting, however, the bias disappears when A-subjects are formed into groups. Thus, the psychological based self-serving bias is neutralized by the psychological forces created by auditor-subjects operating in groups. This suggests that the conclusion drawn by Bazerman et al. (1997) has to be modified. Although self-serving bias can affect decision-making, as suggested by these authors, this bias can be mitigated or neutralized by group affiliation.
Several limitations of this research should be highlighted. First, in order to convert a theoretical model into an experimental setting, certain functions and parameter values must be selected. Although I use functions and parameters consistent with the assumptions of the theory, I do not know how sensitive my findings are to different experimental values. Second, the setting has a game-theoretic basis, and the results may not generalize to market or organizational settings. Third, I used student subjects for the experiment rather than experienced auditors and investors. This may not be a material shortcoming because previous research has shown that student subjects may be most appropriate for testing models that do not incorporate mundane realism (Ball and Ceck 1996). Lastly, the experiment is devoid of context, without mention of fraud, audit, or self-serving bias. As suggested by Haynes and Kachelmeier (1998), the context can play an important role in affecting subject behavior.
Future research could modify my setting to incorporate a more realistic context. One possibility relates to building on the research of Kadous, Kennedy, and Peecher (2000) to investigate how motivated reasoning might affect the strategies of auditor-subjects, especially when there are competing goals from the client and the auditor group members. A second avenue for future research is to investigate how different pair/group configurations can affect the results. For example, it would be interesting to investigate the effect of groups on self-serving bias when the group is formed following the procedures used in practice.
Footnotes
| 1 | The psychology literature on self-serving bias has at least two branches. The branch followed by Bazerman et al. (1997) relates to judgment and decision-making. A second (and related) branch focuses on how individuals attribute success and failures to oneself and to others (Campbell and Sedidides 1999; Mullen and Riordan 1988). See Kaplan and Ruffle (1998;1999) for a discussion of various definitions of self-serving bias. See Lewellen, Park, and Ro (1996) for a discussion of self-serving bias in a financial accounting context. |
| 2 | Bazerman et al. (1997) draw their conclusions about the impossibility of auditor independence based on a number of research articles that found subjects who were assigned different roles, such as plaintiff or defendant, made different decisions on how a judge would decide a case. See Babcock and Lowenstein (1997) for a review of this research. |
| 3 | See Jensen (2000) for a discussion of conflicting accountability for auditors. |
| 4 | For other auditing models see Antle (1984), Beck, Frecka, and Solomon (1988), Bloomfield (1995), Dye (1991), and Fellingham and Newman (1985). |
| 5 | Examples of auditing research using experimental economics include Bloomfield (1997), Calegari, Schatzberg, and Sevcik (1998), Dopuch and King (1991), and Kachelmeier (1991). |
| 6 | In game-theoretic settings, "cheap talk" refers to a form of communication that is costless, nonbinding, nonverifiable, and payoff irrelevant. Crawford (1998) reviews experimental research on cheap talk. |
| 7 | Bamber and Bylinski (1982) and Solomon (1987) review auditing research dealing with groups. |
| 8 | In the field, auditors also have economic ties, thus making group affiliation more important in the field. I did not include economic factors in order to determine whether noneconomic factors alone can undo the self-serving bias. |
| 9 | For research in the area of incentives and decision making, see Bonner et al. (2000), Kennedy (1995), Libby and Lipe (1992), Luft (1994), and Sprinkle (2000). |
| 10 | This situation could arise because M is acting as an agent for the investor and X represents the amount of money that rightfully belongs to the investor but is currently held by the manager. The game is presented as a fraud issue, however, it could be characterized as a reporting decision and retain the same frictions. |
| 11 | I assume audit quality, q(f A) is an increasing function of f A and the cost function, C(q), is increasing, convex, and twice differentiable on q(f A). |
| 12 | The first choice corresponds to a von Stackelberg outcome, the second to a Nash outcome, and the third to an outcome that makes M-subjects indifferent to committing fraud or not. To simplify the model and to make A's reaction function more transparent in the experiment, I constraint A's optimal belief choice to equal M's fraud level. That is, I constrain A's reaction function as follows: f*A = f. This is accomplished by judicious selections of functional forms and parameters, as shown in Table 2. |
| 13 | The numbers calculated from the equations can differ slightly from those used in the experiment due to rounding. The rounding of probabilities is done so that subjects view probabilities with only two digits in order to simplify the presentation. The roundings do not change the predicted equilibrium. |
| 14 | Instructions are available upon request. |
| 15 | The decision not to inform A-subjects of the amount of M-subjects' sanction was done so that A-subjects could not infer M-subjects' fraud levels until the end of the regular play phase. The justification for this approach is that auditors in the field may not learn the client's monetary penalty when fraud is discovered. |
| 16 | However, there may be psychological reasons why this information may affect the decision-making of A-subjects. |
| 17 | This restricted information condition was implemented in order to create a fertile environment for self-serving biases to arise. An interesting question is whether auditors can be leader in a leader/follower game in practice, however this issue is beyond the scope of the current study. |
| 18 | The resolution phase has only six rounds (and the regular play has 18 or more) so that M-subjects are not motivated to use the regular play phase to form reputations and then cheat during the resolution phase. With only six rounds in the resolution phase, the economic return from investing in reputations during the regular play is lessened. M-subjects were informed of the number of rounds in the regular play and resolution phases. A-subjects did not know the number of rounds, but knew there were fewer rounds in the resolution phase than in the regular play phase. |
| 19 | There is a Chinese proverb that states "Listen not to vain words of empty tongue." |
| 20 | Under the WP/WG, SP/WG, and SP/SG settings, five pairs of subjects interacted for 19 rounds and six pairs interacted for 18 rounds during the regular play phase. This generates a total of 203 observations (5 x 19 + 6 x 18 = 203) for these three settings. Under the WP/SG setting, all eleven pairs had 18 rounds during the regular play phase, thus producing 198 observations (11 x 18 = 198). |
| 21 | In the resolution phase, all M- and A-subject pairs played for 6 rounds (6 x 11 = 66) except one pair under the WP/SG setting played only 4 rounds due to network problem. |
| 22 | The random action hypothesis (H1null) is rejected for all four settings. |
References
Antle, R. 1984. Auditor independence. Journal of Accounting Research 22 (Spring): 503-527.
Antle, R, P. Griffin, D. Teece, and O. Williamson. 1997. An economic analysis of auditor independence for a multi-client, multi-service public accounting firm. In Serving the Public Interest: A New Conceptual Framework for Auditor Independence. A report prepared on behalf of the AICPA in connection with the Presentation to the Independence Standards Board.
Ball, S., and P. Cech. 1996. Subject pool choice and treatment effects in economic laboratory research. Research in Experimental Economics 6: 239-92.
Babcock, L. and G. Loewenstein. 1997. Explaining bargaining impasse: The role of self-serving bias. American Economic Review 11 (Winter): 109-126.
Bamber,M. and J. Bylinski. 1982. The audit team and the audit review process: An organizational approach. Journal of Accounting Literature 1: 33-58.
Bazerman, M., K. Morgan, and G. Loewenstein. 1997. The impossibility of auditor independence. Sloan Management Review (Summer): 89-94.
Beck, P. J., T. Frecka, and I. Solomon, 1988. A model of the market for MAS and audit services: Implications for auditor independence. Journal of Accounting Literature 7:50-64.
Berg, J. J. Dickhaut, K. McCabe. 1995. Trust, reciprocity, and social history. Games and Economic Behavior 10: 122-142.
Bloomfield, R., 1995, Strategic dependence and inherent risk assessments, The Accounting Review 70 (January): 71-90.
Bloomfield, R. 1997. Strategic dependence and the assessment of fraud risk: A laboratory study. The Accounting Review 72 (October): 517-538.
Bonner, S., R. Hastie, G. Sprinkle, and M. Young. 2000. A review of the effects of financial incentives on performance in laboratory tasks: Implications for management accounting. USC Working paper.
Burke, W. 1997. Auditor independence: An Organizational Psychology Perspective. In Serving the Public Interest: A New Conceptual Framework for Auditor Independence. A report prepared on behalf of the AICPA in connection with the Presentation to the Independence Standards Board.
Calegari, M., J. Schatzberg, and G. Sevcik. 1998. Experimental Evidence of Differential Auditor Pricing and Reporting Strategies. The Accounting Review 73 (April): 255-275.
Camerer, C. 1997. Progress in behavioral game theory. Journal of Economic Perspectives 11 (4): 167-188.
Campbell, W., and C. Sedikides. 1999. Self-threat magnifies the self-serving bias: A meta-analytic integration. Review of General Psychology 3, No.1: 23-43
Cooper, R., D. DeJong, R. Forsythe, and T. Ross. 1989. Communication in the battle of the sexes: Some experimental results. Rand Journal of Economics 20: 568-587
Cooper, R., D. DeJong, R. Forsythe, and T. Ross. 1992. Communication in coordination games. Quarterly Journal of Economics 20: 568-587
Craswell, A, and J. Francis. 1999. Pricing initial audit engagements: A test of competing theories, The Accounting Review 74 (April): 201-216.
Crawford, V. 1998. A survey of experiments on communication via cheap talk. Journal of Economic Theory 78: 286-298.
Davis, D. and C. Holt. 1993. Experimental Economics. Princeton University Press, New Jersey.
Dawes, R., and R. Thaler. 1988. Anomalies: Cooperation. Journal of Economic Perspectives 2 (Summer): 187-197.
DeAngelo, L. 1981. Auditor independence, `low-balling' and disclosure regulations. Journal of Accounting and Economics 3 (December): 113-127.
Dopuch, N., R. King. 1991. The impact of MAS on auditor independence: An experimental markets study, Journal of Accounting Research 29 (Supplement): 60-98.
Duh, R. and S. Sunder. 1986. Incentives, learning and processing of information in a market environment: An examination of the base-rate fallacy. In S. Moriarty , ed. Laboratory Market Research, Norman OK: Center of Economic and Management Research, University of Oklahoma.
Dye, R. 1991. Informationally motivated auditor replacement. Journal of Accounting and Economics 14 (December): 347-374.
Edgington, E. 1980. Randomization Tests. New York, NY: Marcell Dekker.
Elliott, R. and P. Jacobson. 1992. Audit independence: Concepts and application, The CPA Journal (March): 34-39.
Fardella, J, R., Hollander-Blumoff, B. Fleischer, R. Fukuyama, and A. Klosterman. 2000. Report of the internal investigation of independence issues at PriceWaterhouseCoopers LLP; In the matter of PriceWaterhouseCoopers LLP. Filed with the U.S Securities and Exchange Commission (AP file 3-9809-January 6).
Fellingham, J. and D. Newman. 1985. Strategic considerations in auditing. The Accounting Review 60 (October): 634-650.
General Accounting Office. 1996. The Accounting Profession-Major Issues: Progress And Concerns. Report to the Ranking Minority Member, Committee on Commerce, House of Representatives (September)
Haynes, C., and S. Kachelmeier. 1998. The effects of accounting contexts on accounting decisions: A synthesis of cognitive and economic perspectives in accounting experimentation. Journal of Accounting Literature 17: 97-136.
Ho, D. 1976. On the concept of face. American Journal of Sociology (January): 867-884.
Jensen, K. 2000. Conflicting accountability and auditors' decision behaviors. Working paper University of Oklahoma.
Kachelmeier, S., and M. Shehata. 1997. Internal auditing and voluntary cooperation in firms: Across cultural experiment. The Accounting Review 72 (3): 407-431.
Kachelmeier, S. 1996a. Discussion of "Tax advice and reporting under uncertainty: Theory and experimental evidence." Contemporary Accounting Research 13 (1): 81-89.
Kachelmeier, S. 1996b. Do cosmetic reporting variations affect market behavior? A laboratory study of the accounting emphasis on unavoidable costs. Review of Accounting Studies 1 (2): 115-140.
Kachelmeier, S. 1991. A laboratory market investigation of the demand for auditing in an environment of moral hazard. Auditing: A Journal of Practice and Theory 11 (Supplement): 25-48.
Kadous, K., J. Kennedy, and M. Peecher. 2000. Can accuracy goals reduce auditor objectivity? Working paper University of Washington and University of Illinois.
Kaplan, T. and B. Ruffle. 1998. Self-serving Bias. American Economics Review 12 :243-244.
Kaplan, T. and B. Ruffle. 1999. Self-serving bias and beliefs about rationality. Working paper, Ben-Gurion University.
Kennedy, J. 1995. Debiasing the curse of knowledge in audit judgment. The Accounting Review 70 (April): 249-273.
King, R. 1991. Using experimental economics in auditing research, In Auditing: Advances in Behavioral Research. Series: Recent Research in Psychology. Editors, L. Ponemon and D. Gabhart: 93-112.
King, R and R.Schwartz. 2000. An experimental investigation of auditors' liability: Implications for social welfare and explorations of deviations from theoretical predictions. The Accounting Review (forthcoming).
Kreps, D. 1990. A Course in Microeconomic Theory. Princeton University Press.
Libby, R., and M. Lipe. 1992. Incentive effects and the cognitive processes involved in accounting judgments. Journal of Accounting Research 30 (Autumn): 249-273.
Libby, R., R. Bloomfield, and M. Nelson. 2000. Experimental research in financial accounting. To be presented at the Accounting, Organizations, and Society 25th Anniversary conference.
MacDonald, E. 1999. SEC's Levitt sharply criticizes auditors and suggests they need better policing. Wallstreet Journal (October 8): http://interactive.wsj.com/articles.
McCabe, K., S. Rassenti, and V. Smith. 1998. Reciprocity, trust, and payoff privacy in extensive form bargaining. Games and Economic Behavior 24: 10-24.
Mullen, B., and C. Riordan. 1988. Self-serving attributions for performance in naturalistic settings: A meta-analytic review. Journal of Applied Social Psychology 18 (No 1): 3-22.
Lewellen, W. T. Park, and B. Ro. 1996. Self-serving behavior in mangers' discretionary information disclosure decisions. Journal of Accounting and Economics 22 (April):227-251.
Luft, J. 1994. Bonus and penalty incentives: Contract choice by employees. Journal of Accounting and Economics 18 (September): 181-206.
Palmrose, Z. 1994. The joint & several versus proportionate liability debate: An empirical investigation of audit-related litigation. Stanford Journal of Law, Business & Finance 1 (Fall): 53-72.
Pitt, H. and D. Birenbaum. 1997. Serving the Public Interest: A new Conceptual Framework for Auditor Independence. A report prepared on behalf of the AICPA in connection with the Presentation to the Independence Standards Board.
Public Oversight Board Advisory Panel On Auditor Independence. 1994. Strengthening the professionalism of the independent auditor (September)
Report by the Panel on Audit Effectiveness. 2000. Public Oversight Board (May 31).
Solomon, I. 1987. Multi-auditor judgment/decision making research. Journal of Accounting Literature 6: 1-25.
Sprinkle, G. 2000. The effect of incentive contracts on learning and performance. The Accounting Review (75): 299-326 .
United States Senate. 1977. Improving the accountability of publicly owned corporations and their auditors: Report of the Subcommittee on Reports, Accounting, And Management of The Committee on Government Operations. Washington D.C.: U.S. Government Printing Office.
Wallman, S. 1996. The future of accounting, Part III: Reliability and auditor independence. Accounting Horizon (December): 76-97.
 Figure 1: M-subject's Computer Screen Under Strong Pair/Strong Group Setting
Figure 1: M-subject's Computer Screen Under Strong Pair/Strong Group Setting Figure 2: A-subject's Computer Screen Under Strong Pair/Strong Group Setting
Figure 2: A-subject's Computer Screen Under Strong Pair/Strong Group Setting